Databricks
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST · Question #64
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Question #64: Real Exam Question with Answer & Explanation
Sign in or unlock DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST to reveal the answer and full explanation for question #64. The question stem and answer options stay visible for context.
Question
You are building a classifier off of a very high-dimensiona data set similar to shown in the image with 5000 variables (lots of columns, not that many rows). It can handle both dense and sparse input. Which technique is most suitable, and why?
Exhibit
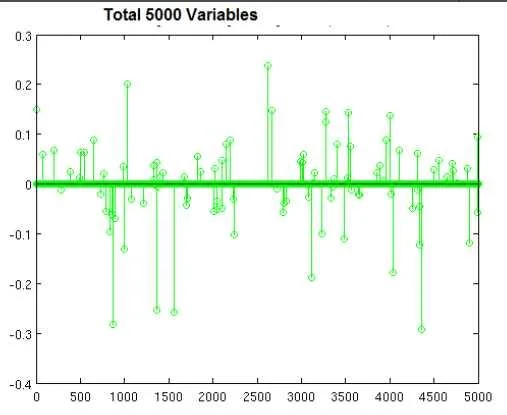
Options
- ALogistic regression with L1 regularization, to prevent overfitting
- BNaive Bayes, because Bayesian methods act as regularlizers
- Ck-nearest neighbors, because it uses local neighborhoods to classify examples
- DRandom forest because it is an ensemble method
Unlock DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST to see the answer
You've previewed enough free DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST questions. Unlock DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST for full answers, explanations, the timed quiz mode, progress tracking, and the master PDF. Question stem and options stay visible so you can still see what's on the exam.