SOL-C01 · Question #178
You are tasked with loading JSON log files stored in an external stage named "s3_logs' into a Snowflake table called 'raw_logs'. The JSON files contain a 'timestamp' field as a string, and you need to
Sign in or unlock SOL-C01 to reveal the answer and full explanation for question #178. The question stem and answer options stay visible for context.
Question
You are tasked with loading JSON log files stored in an external stage named "s3_logs' into a Snowflake table called 'raw_logs'. The JSON files contain a 'timestamp' field as a string, and you need to ensure that the 'raw_logs' table contains a valid Snowflake timestamp. The stage 's3_logS points to an S3 bucket that has hundreds of JSON log files. You want to use a directory table to incrementally load new files. Which of the following sequences of commands would be the MOST efficient and correct way to achieve this? Assume the directory table already exists and is refreshed periodically. Also, assume the 'raw_logs' table has a variant column named 'raw data' and a timestamp column named 'log_time'
Exhibit
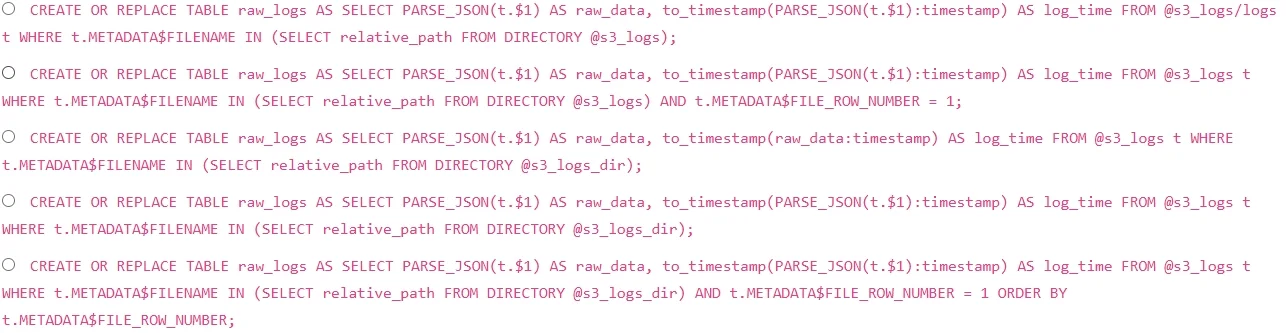
Options
- AOption A
- BOption B
- COption C
- DOption D
- EOption E
Unlock SOL-C01 to see the answer
You've previewed enough free SOL-C01 questions. Unlock SOL-C01 for full answers, explanations, the timed quiz mode, progress tracking, and the master PDF. Question stem and options stay visible so you can still see what's on the exam.