MLS-C01 · Question #184
A data scientist is training a text classification model by using the Amazon SageMaker built-in BlazingText algorithm. There are 5 classes in the dataset, with 300 samples for category A, 292 samples
Sign in or unlock MLS-C01 to reveal the answer and full explanation for question #184. The question stem and answer options stay visible for context.
Question
A data scientist is training a text classification model by using the Amazon SageMaker built-in BlazingText algorithm. There are 5 classes in the dataset, with 300 samples for category A, 292 samples for category B, 240 samples for category C, 258 samples for category D, and 310 samples for category E. The data scientist shuffles the data and splits off 10% for testing. After training the model, the data scientist generates confusion matrices for the training and test sets. What could the data scientist conclude form these results?
Exhibits
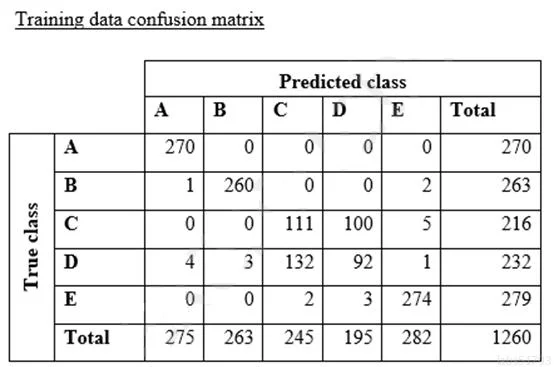
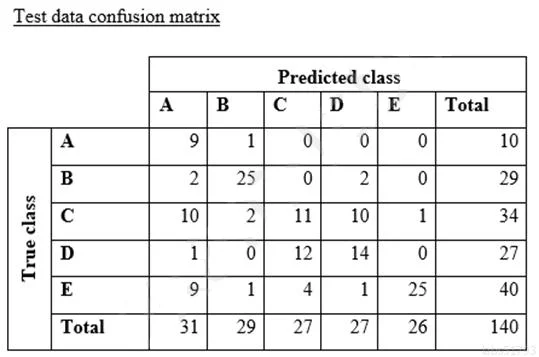
Options
- AClasses C and D are too similar.
- BThe dataset is too small for holdout cross-validation.
- CThe data distribution is skewed.
- DThe model is overfitting for classes B and E.
Unlock MLS-C01 to see the answer
You've previewed enough free MLS-C01 questions. Unlock MLS-C01 for full answers, explanations, the timed quiz mode, progress tracking, and the master PDF. Question stem and options stay visible so you can still see what's on the exam.