Microsoft
DP-300 · Question #139
Hotspot Question You are performing exploratory analysis of bus fare data in an Azure Data Lake Storage Gen2 account by using an Azure Synapse Analytics serverless SQL pool. You execute the Transact-S
Sign in or unlock DP-300 to reveal the answer and full explanation for question #139. The question stem and answer options stay visible for context.
Submitted by kim_seoul· Mar 6, 2026Optimize query performance
Question
Hotspot Question You are performing exploratory analysis of bus fare data in an Azure Data Lake Storage Gen2 account by using an Azure Synapse Analytics serverless SQL pool. You execute the Transact-SQL query shown in the following exhibit. Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. Answer:
Exhibits
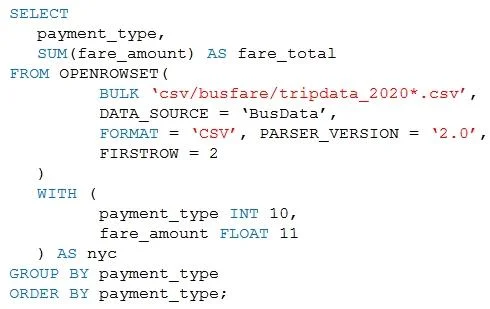
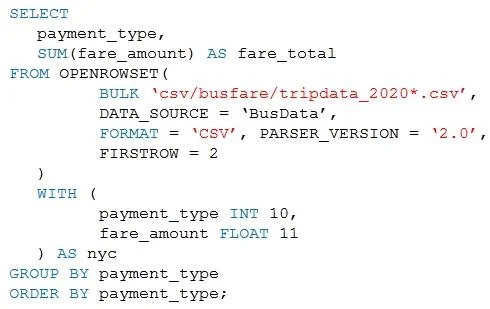
Answer Area
- The query results include only [answer choice] in the csv/busfare folder.CSV files in the tripdata_2020 subfolderfiles that have file names beginning with "tripdata_2020"CSV files that have file names containing "tripdata_202"CSV files that have file named beginning with "tripdata_2020"
- The query assumes that the first row in a CSV file is [answer choice] row.a headera dataan empty
Unlock DP-300 to see the answer
You've previewed enough free DP-300 questions. Unlock DP-300 for full answers, explanations, the timed quiz mode, progress tracking, and the master PDF. Question stem and options stay visible so you can still see what's on the exam.
Topics
#Azure Synapse Analytics#serverless SQL pool#OPENROWSET#Azure Data Lake Storage Gen2#CSV files