DP-300 · Question #133
Hotspot Question You plan to develop a dataset named Purchases by using Azure Databricks. Purchases will contain the following columns: - ProductID - ItemPrice - LineTotal - Quantity - StoreID - Minut
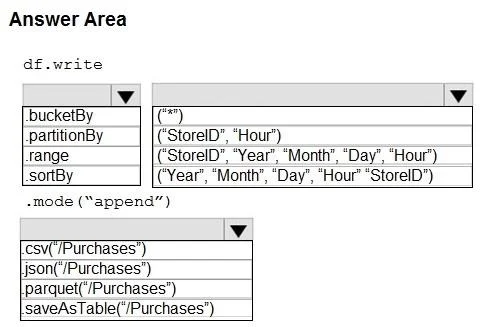
The correct answer is df.write method: .partitionBy; method arguments: ("StoreID", "Hour"); final write action: .parquet("/Purchases"). This question tests knowledge of Delta Lake partitioning strategies in Azure Databricks to optimize storage and query performance for incremental load pipelines.
Question
Exhibit
Answer Area
- df.write method.partitionBy.bucketBy.partitionBy.range.sortBy
- method arguments("StoreID", "Hour")("*")("StoreID", "Hour")("StoreID", "Year", "Month", "Day", "Hour")("Year", "Month", "Day", "Hour", "StoreID")
- final write action.parquet("/Purchases").csv("/Purchases").json("/Purchases").parquet("/Purchases").saveAsTable("/Purchases")
Explanation
This question tests knowledge of Delta Lake partitioning strategies in Azure Databricks to optimize storage and query performance for incremental load pipelines.
Approach. The correct approach is to use Delta format with partitioning on StoreID and then time-based columns (Year, Month, Day, Hour) in that order. The code should use partitionBy('StoreID', 'Year', 'Month', 'Day', 'Hour') when writing the DataFrame, because the pipelines vary per StoreID and run hourly, meaning partitioning by StoreID first allows efficient pruning per store, and then hierarchical time partitioning (Year > Month > Day > Hour) enables incremental hourly loads to only touch the relevant partition directories. This minimizes storage costs by avoiding full table scans and rewrites - only the relevant hour/store partition is updated during each incremental load. Using Delta format also enables ACID transactions and partition overwrite, which is essential for reliable incremental pipelines.
Concept tested. Delta Lake partitioning strategy in Azure Databricks - specifically choosing the correct partition columns and their order to optimize incremental load pipelines that are scoped by StoreID and time (hourly), while minimizing storage overhead and unnecessary data reads/writes.
Reference. Microsoft Learn: Optimize Delta Lake for Azure Databricks - https://learn.microsoft.com/en-us/azure/databricks/delta/best-practices#choose-the-right-partition-column
Topics
Community Discussion
No community discussion yet for this question.