Microsoft
DP-203 · Question #96
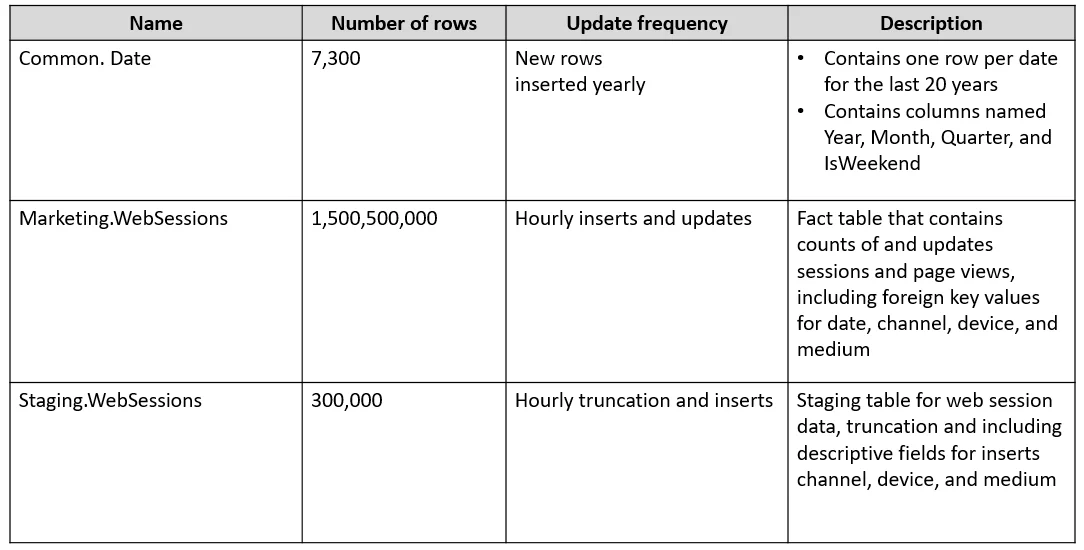
Drag and Drop Question You have an Azure subscription. You plan to build a data warehouse in an Azure Synapse Analytics dedicated SQL pool named pool1 that will contain staging tables and a dimensiona
Sign in or unlock DP-203 to reveal the answer and full explanation for question #96. The question stem and answer options stay visible for context.
Submitted by kavita_s· Mar 30, 2026Design and Implement Data Storage - specifically designing distributed table strategies in Azure Synapse Analytics dedicated SQL pools to optimize both data loading and query performance.
Question
Drag and Drop Question You have an Azure subscription. You plan to build a data warehouse in an Azure Synapse Analytics dedicated SQL pool named pool1 that will contain staging tables and a dimensional model. Pool1 will contain the following tables. You need to design the table storage for pool1. The solution must meet the following requirements: - Maximize the performance of data loading operations to Staging.WebSessions. - Minimize query times for reporting queries against the dimensional model. Which type of table distribution should you use for each table? To answer, drag the appropriate table distribution types to the correct tables. Each table distribution type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Answer:
Exhibit
Answer Area
Drag items
HashReplicatedRound-robin
Unlock DP-203 to see the answer
You've previewed enough free DP-203 questions. Unlock DP-203 for full answers, explanations, the timed quiz mode, progress tracking, and the master PDF. Question stem and options stay visible so you can still see what's on the exam.
Topics
#Azure Synapse Analytics#Dedicated SQL Pool#Table Distribution#Data Warehouse Design