Microsoft
DP-203 · Question #277
Drag and Drop Question You use PySpark in Azure Databricks to parse the following JSON input. You need to output the data in the following tabular format. How should you complete the PySpark code? To
Sign in or unlock DP-203 to reveal the answer and full explanation for question #277. The question stem and answer options stay visible for context.
Submitted by wei.xz· Mar 30, 2026Design and implement data engineering workloads using Azure Databricks, including transforming semi-structured data (JSON) into structured tabular formats using PySpark DataFrame APIs - typically aligned with the 'Implement data transformation' or 'Process and serve data' domain of the DP-203 Azure Data Engineer Associate certification.
Question
Drag and Drop Question You use PySpark in Azure Databricks to parse the following JSON input. You need to output the data in the following tabular format. How should you complete the PySpark code? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the spit bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Answer:
Exhibit
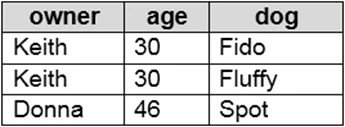
Answer Area
Drag items
aliasarray_unioncreateDataFrameexplodeselecttranslate
Unlock DP-203 to see the answer
You've previewed enough free DP-203 questions. Unlock DP-203 for full answers, explanations, the timed quiz mode, progress tracking, and the master PDF. Question stem and options stay visible so you can still see what's on the exam.
Topics
#PySpark#Azure Databricks#JSON Parsing#DataFrame Operations#explode() function