Microsoft
DP-100 · Question #548
Drag and Drop Question You manage an Azure AI Foundry project. You deploy a large language model from the model catalog. You need to manually evaluate the model, collect the statistics, and be able to
Sign in or unlock DP-100 to reveal the answer and full explanation for question #548. The question stem and answer options stay visible for context.
Optimize language models for AI applications
Question
Drag and Drop Question You manage an Azure AI Foundry project. You deploy a large language model from the model catalog. You need to manually evaluate the model, collect the statistics, and be able to review the results later. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Answer:
Exhibit
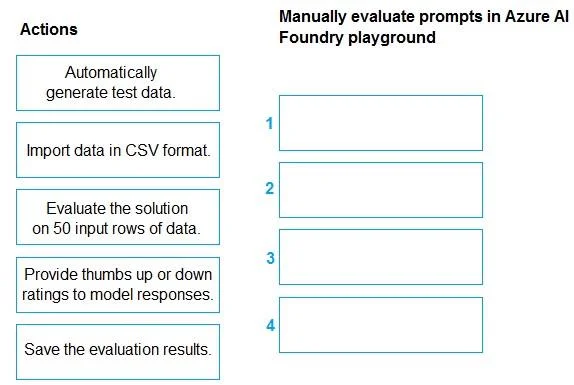
Answer Area
Drag items
Automatically generate test data.Import data in CSV format.Evaluate the solution on 50 input rows of data.Provide thumbs up or down ratings to model responses.Save the evaluation results.
Unlock DP-100 to see the answer
You've previewed enough free DP-100 questions. Unlock DP-100 for full answers, explanations, the timed quiz mode, progress tracking, and the master PDF. Question stem and options stay visible so you can still see what's on the exam.
Topics
#LLM Evaluation#Manual Evaluation#Azure AI Foundry#Evaluation Workflow