Microsoft
DP-100 · Question #518
Drag and Drop Question You design a project for interactive data wrangling with Apache Spark in an Azure Machine Learning workspace. The data pipeline must provide the following solution: - Ingest and
Sign in or unlock DP-100 to reveal the answer and full explanation for question #518. The question stem and answer options stay visible for context.
Explore data and run experiments
Question
Drag and Drop Question You design a project for interactive data wrangling with Apache Spark in an Azure Machine Learning workspace. The data pipeline must provide the following solution: - Ingest and process a vast amount of data from various sources and linked services, such as databases and APIs. - Visualize the results in Microsoft Power Bl. - Include a possibility to quickly identify and address issues by observing only a small amount of data using the fewest resources. You need to select a computation option for project activities. Which compute option should you select for the different activities? To answer, move the appropriate compute options to the correct project activities. You may use each compute option once, more than once, or not at all. You may need to move the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Answer:
Exhibit
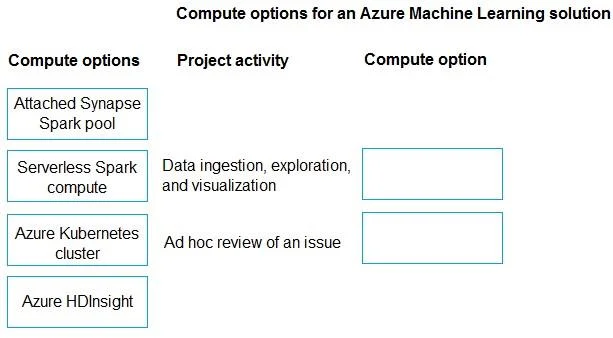
Answer Area
Drag items
Attached Synapse Spark poolServerless Spark computeAzure Kubernetes clusterAzure HDInsight
Unlock DP-100 to see the answer
You've previewed enough free DP-100 questions. Unlock DP-100 for full answers, explanations, the timed quiz mode, progress tracking, and the master PDF. Question stem and options stay visible so you can still see what's on the exam.
Topics
#Azure Machine Learning#Apache Spark#Compute Options#Data Wrangling