Microsoft
DP-100 · Question #509
Drag and Drop Question You create an Azure Machine Learning workspace. You are training a classification model with no-code AutoML in Azure Machine Learning studio. The model must predict if a client
Sign in or unlock DP-100 to reveal the answer and full explanation for question #509. The question stem and answer options stay visible for context.
Explore data and run experiments
Question
Drag and Drop Question You create an Azure Machine Learning workspace. You are training a classification model with no-code AutoML in Azure Machine Learning studio. The model must predict if a client of a financial institution will subscribe to a fixed-term deposit. You must preview the data profile in Azure Machine Learning studio once the dataset is created. You need to train the model. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Answer:
Exhibit
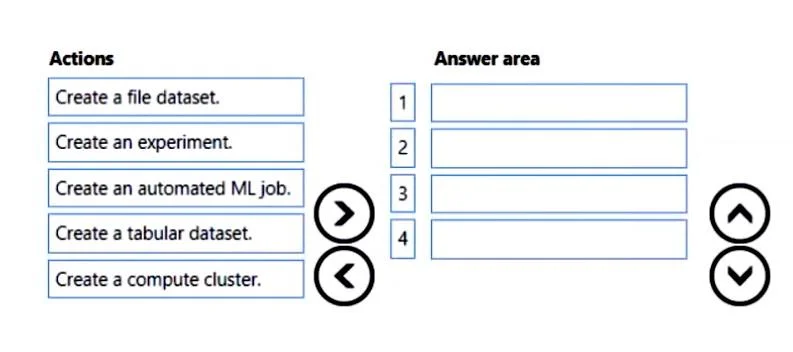
Answer Area
Drag items
Create a file dataset.Create an experiment.Create an automated ML job.Create a tabular dataset.Create a compute cluster.
Unlock DP-100 to see the answer
You've previewed enough free DP-100 questions. Unlock DP-100 for full answers, explanations, the timed quiz mode, progress tracking, and the master PDF. Question stem and options stay visible so you can still see what's on the exam.
Topics
#Azure Machine Learning#AutoML#Model Training Workflow#Data Profiling