Microsoft
DP-100 · Question #473
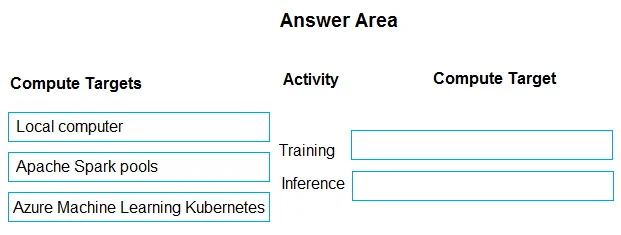
Drag and Drop Question You are designing an Azure Machine Learning solution by using the Python SDK v2. You must train and deploy the solution by using a compute target. The compute target must meet t
Sign in or unlock DP-100 to reveal the answer and full explanation for question #473. The question stem and answer options stay visible for context.
Train and deploy models
Question
Drag and Drop Question You are designing an Azure Machine Learning solution by using the Python SDK v2. You must train and deploy the solution by using a compute target. The compute target must meet the following requirements: - Enable the use of on-premises compute resources. - Support autoscaling. You need to configure a compute target for training and inference. Which compute targets should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Answer:
Exhibit
Answer Area
Drag items
Local computerApache Spark poolsAzure Machine Learning Kubernetes
Unlock DP-100 to see the answer
You've previewed enough free DP-100 questions. Unlock DP-100 for full answers, explanations, the timed quiz mode, progress tracking, and the master PDF. Question stem and options stay visible so you can still see what's on the exam.
Topics
#Azure ML Compute Targets#Azure Arc#Kubernetes#Autoscaling